11-3. K최근접 이웃 알고리즘
k 최근접 이웃 알고리즘(k-Nearest Neighbor,kNN, Algorithm)
특징 공간에서 테스트 데이터와 가장 가까이 있는 k개의 학습 데이터를 찾아 분류 또는 회귀를 수행하는 지도 학습(Supervised Learning) 알고리즘의 하나

KNN 알고리즘 객체 생성: cv2.ml.KNearest_create() -> <cv2.ml_KNearest Object>
* <cv2.ml_StatModel>클래스를 상속 받은 객체기 때문에 predict 함수로도 입력 데이터의 클래스 예측 구현은 가능하다.
KNN 알고리즘으로 입력 데이터의 클래스 예측: <cv2.ml_KNearest Object>.findNearest(samples, k, results, neighborResponses, dist, flags) -> retval, results, neighborResponses, dist
samples는 (N,d) 크기 및 np.float32 데이터 형식의 np.ndarray 형태의 입력 벡터가 행 단위로 저장된 입력 샘플 행렬
k는 사용할 최근접 이웃 개수 (predict 함수 사용할 때보다 직접적으로 세팅할 수 있음)
results는 (N,1) 크기 및 np.float32 데이터 형식의 np.ndarray 형태의 각 입력 샘플에 대한 예측 결과를 저장한 행렬
neighborResponses는 (N,k) 크기 및 np.float32 데이터 형식의 np.ndarray 형태의 예측에 사용된 k개의 최근점 이웃 클래스 정보 행렬
dist는 (N,k) 크기 및 np.float32 데이터 형식의 np.ndarray 형태의 입력 벡터와 예측에 사용된 k개의 최근접 이숫과의 거리를 저장한 행렬
retval은 입력 벡터가 하나인 경우에 대한 응답
아래는 kNN을 이용하여 점을 분류하는 예제 수행 결과이다.


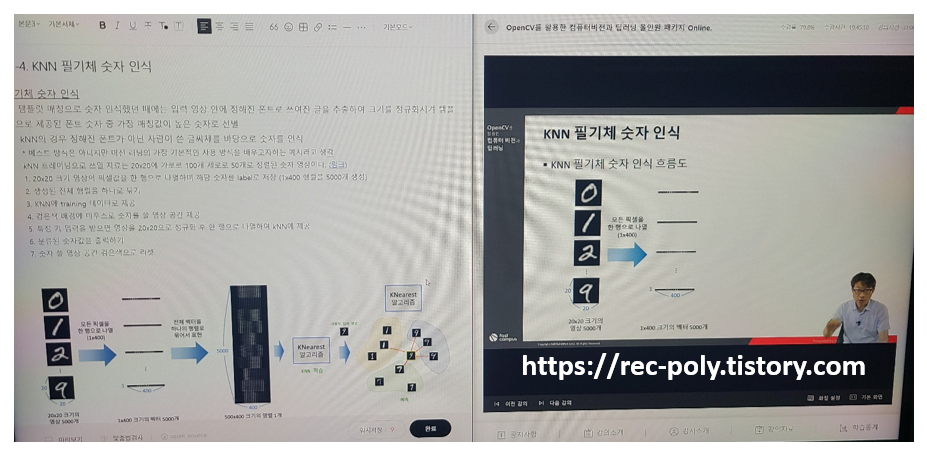
11-4. KNN 필기체 숫자 인식
필기체 숫자 인식
템플릿 매칭으로 숫자 인식했던 때에는 입력 영상 안에 정해진 폰트로 쓰여진 글을 추출하여 크기를 정규화시켜 템플릿으로 제공된 폰트 숫자 중 가장 매칭값이 높은 숫자로 선별
kNN의 경우 정해진 폰트가 아닌 사람이 쓴 글씨체를 바탕으로 숫자를 인식
* 베스트 방식은 아니지만 머신 러닝의 가장 기본적인 사용 방식을 배우고자하는 예시라고 생각 (실제 입력이 창에서 글자가 한 쪽에 쏠리게 되면 트레이닝 된 데이터는 그에 대한 케이스는 커버하지 못하기 때문에 정확도가 떨어진다.)
kNN 트레이닝으로 쓰일 자료는 20x20에 가로로 100개 세로로 50개로 정렬된 숫자 영상이다. (링크)
1. 20x20 크기 영상의 픽셀값을 한 행으로 나열하며 해당 숫자를 label로 저장 (1x400 행렬을 5000개 생성)
2. 생성된 전체 행렬을 하나로 묶기
3. KNN에 training 데이터로 제공
4. 검은색 배경에 마우스로 숫자를 쓸 영상 공간 제공
5. 특정 키 입력을 받으면 영상을 20x20으로 정규화 후 한 행으로 나열하여 kNN에 제공
6. 분류된 숫자값을 출력하기
7. 숫자 쓸 영상 공간 검은색으로 리셋

동영상 서비스가 종료되어 해당 콘텐츠를 재생할 수 없습니다.
인증 타임
템플릿 매칭 때도 신기 했지만 이번에는 직접 쓴 글씨의 숫자를 머신 러닝 알고리즘을 이용하여 숫자를 분류하는게 신기했다. 실제 사용 정확도는 좀 떨어졌는데 다른 머신 러닝 알고리즘을 사용한다던가 특징 벡터 추출 방식을 다르게 하면 어디까지 퍼포먼스가 더 증가할 수 있을지 궁금하다.

#패스트캠퍼스 #패캠챌린지 #직장인인강 #직장인자기계발 #패스트캠퍼스후기 #OpenCV를 활용한 컴퓨터비전과 딥러닝 올인원 패키지 Online
패스트캠퍼스(FastCampus) 강의 둘러보러 가기
↓ ↓ ↓
패스트캠퍼스 [직장인 실무교육]
프로그래밍, 영상편집, UX/UI, 마케팅, 데이터 분석, 엑셀강의, The RED, 국비지원, 기업교육, 서비스 제공.
fastcampus.co.kr
본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성되었습니다.
'남돈내배 > 2022_FastCampus_환급이벤트' 카테고리의 다른 글
| 패스트캠퍼스 챌린지 45일차 - Ch11. 머신 러닝 (0) | 2022.03.09 |
|---|---|
| 패스트캠퍼스 챌린지 44일차 - Ch11. 머신 러닝 (0) | 2022.03.08 |
| 패스트캠퍼스 챌린지 42일차 - Ch11. 머신 러닝 (0) | 2022.03.06 |
| 패스트캠퍼스 챌린지 41일차 - Ch10. 객체 추적과 모션 벡터 (0) | 2022.03.05 |
| 패스트캠퍼스 챌린지 40일차 - Ch10. 객체 추적과 모션 벡터 (0) | 2022.03.04 |